This is part one of a series of posts I’m going to do about SecondHand’s AI, check out the intro here.
Problem Definition:
Since SecondHand has heavy emphasis on melee combat, for the enemies to be challenging and dangerous they need to be able to reach a position where they can attack. This is especially challenging given the twin-stick nature of the game combined with high physicality. The problem is compounded by the high number of enemies and the multiplayer aspect.
Simply put, the problem we’re trying to solve is: what is the best position for an enemy agent to be at any time?
Challenges:
- different enemies have different preferred locations depending on range and personality (some prefer to flank, others prefer to attack head on)
- lots of enemy agents at the same time
- multiple targets
- a varied environment
- chaotic & physical combat
- needs to be easy to set up
But what I consider one of the most important aspects is that it needs to be robust. Why? Because AI robustness goes hand in hand with good level design and balancing.
Our 3-step solution:
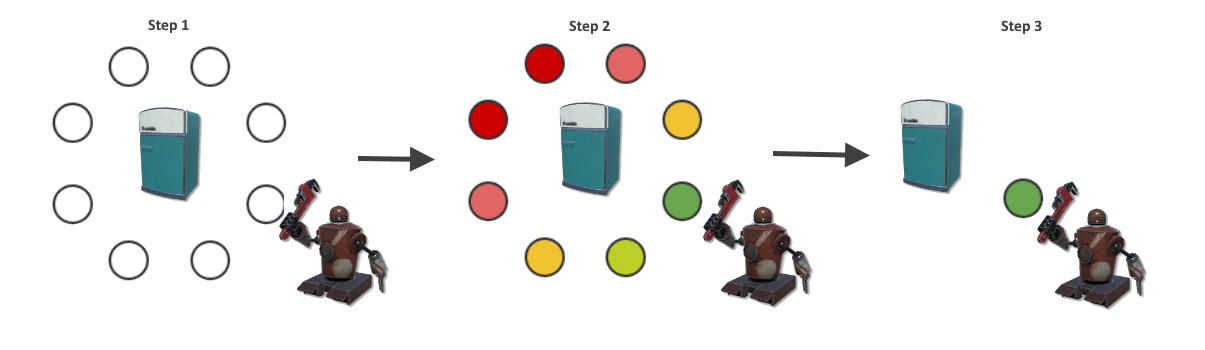
Step 1: sample positions around the player
Step 2: score those positions (make this part easily extended and parametric)
Step 3: pick one to use based on the scores.
This is how the end result looks like, pay attention to how the enemies bunch up around the players:
Let’s cover the steps into more detail.
Step 1: Sample generation and filtering
The player is the target, so we’re going to sample positions around the player’s position. Since multiple enemies are attacking the player, we want that “being surrounded” flavour to the action so we’ll start out by generating concentric rings of positions. We update these positions every frame.
Architecturally speaking, we abstract the generation into a SamplePositionGenerator that provides points to the positioning module. So we can have any number of generators that generate any number of points.
Here’s our radial positions generator doing its thing:
So now we have some points, but obviously some are invalid due to them being off navmesh. We need to filter those out. Let’s build a Filter that takes a point, that does a nav-mesh line of sight check towards the center. No use going to that position if the enemy can’t see the player, right?
Ok, so we have some candidate positions at this point. Onward to scoring!
Step 2: Sample scoring
Everything that happens from this point forward is enemy centric. Each enemy agent will have its own scoring stack and parameters (for those worrying about performance, I’ll talk about that later).
Each position needs to be evaluated and given a score, and we want the scoring to parametric. This is why we create multiple scoring stages that we can stack and form a final score.
In diagram form, the process looks something like this:
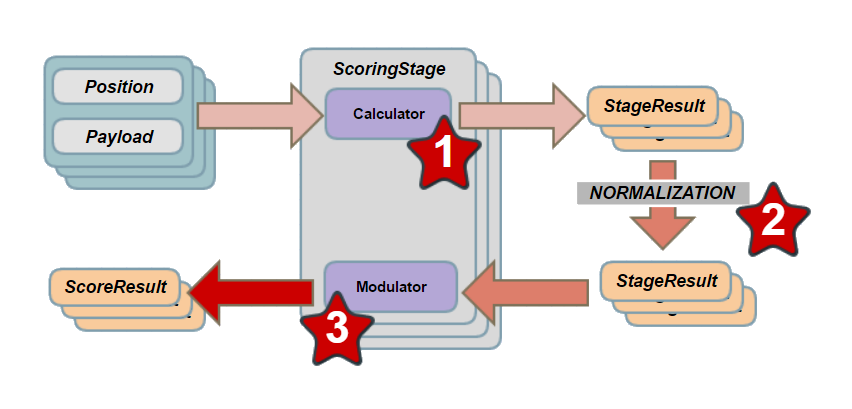
In the diagram above, we construct scoring stages that have a score calculator (evaluates and scores a position) and a modulator (modulates normalized scores). We feed in positions, score them, normalize the scores into 0 – 1 range, and then apply things like falloff, inversion and weight. You can follow the flow of data based on the numbered stars.
What’s the payload you might be asking. The payload contains data needed by some calculators, such as the positions of the other enemies or the parent of the position being evaluated. The position itself is contained in the payload but for the sake of clarity, the diagram shows it as separate.
Modulation is separate because it needs normalized scores to function. It also biases the results based on the stages weight. So when combining results, if distance to the target is more important the distance stage will have more weight in the stack. The types of modulation available are Inverse, Power with custom exponent, Inverse-Square.
I’m going to show you how a stack looks and behaves in practice. Let’s start with a simple distance to target. Each enemy has a preferred distance to its target. A parametric distance stage result will look like this:
Remember, it’s important that the scoring function should be something really simple like distance, dot product, average distance to other agents, etc. Also, if the function is parametric it becomes reusable and a very good tool in creating personality with the same building blocks.
Note that in the distance example, the preferred distance is the parameter that varies.
Here’s the preferred_distance parameter changing at runtime.
In the distance example, you can see modulation at work.Inverse being applied, but also the pow function with a varying exponent to make the “habitable” zone thinner or wider.
Here’s another example with dot product between A (enemy pos, position) and B (position, target pos). Functionally, we’re telling the enemy he prefers points between the player and himself. We’re messing with the pow exponent to create wider or narrower cones.
Now lets combine the two and have an enemy follow the best point.
Let’s try a fun one. We don’t want the enemies to get trapped in corners, we want them to stay away from walls. Let’s create a stage that scores point distance to the edge of the navmesh.
The multi-agent problem
At this point we’re ready to tackle the problem of multiple enemies competing for positions. When adding two enemies, it’s very much imaginable that they can choose the same point. How do we prevent that?
First idea: score the distance to other enemies, and invert the result. That will cause the points close to others to have a lower scores and the best points to be the ones farther away. Alas, this doesn’t work well in practice, because everyone is moving and influencing everyone else! What happens is oscillation, the agents will continuously change their minds and run around aimlessly.
A better idea: score point distance to the other enemies intended position. This provides a stable solution and solves the decision oscillation.
Did I mention we implemented priorities? Damn right we did — lower prio enemies get out of the way of higher prio ones. Here’s how it looks (red guy has lower priority):
Here’s some emergent order from using these really simple functions. Notice how the agents make room for a higher priority peer (the green guy that pops up):
Step 3: Choosing the final result
This is the final step and is a straightforward one. The simplest approach is to simply choose the best scoring position, but there are some alternatives that include choosing a random sample in the top x% scores.
Its also worth mentioning that you can implement decision inertia at this point. For example, keep using the same point if its score doesn’t drop below a certain threshold, or only change if the score has dropped %x percent in the last y timeframe.
Even though the system works with any number of players providing positions, we are currently using a different method to select the target player, to prevent decision oscillations where the enemy agent keeps changing its mind about its target.
Caveats & Opportunities
The scoring method described is very powerful and straightforward, but it can be very hard to debug when dealing with a lot of scoring stages. Why? Because nonlinearities get added up and form non intuitive results. A way to mitigate this is to keep stage stacks small and swap between them based on the situation( for example have one stack the the enemy is far away, and another one if it is close).
Our implementation is currently unoptimized and it currently runs fine. But that’s not to say that it couldn’t cause problems in the future. Let’s look at some numbers, say we have 10 enemy agents on screen and 2 players. If each player generates 90 points, we’re looking at 10 x 2 x 90 nav-mesh queries per frame, yikes! There’s plenty of ways to mitigate this and this topic deserves its own blogpost, but generally spreading out computation across frames is a good approach.
That’s it for this episode from the trenches. Ping me on twitter @Radu_Septimiu if you’d like to discuss this stuff or have any questions.
Radu out.